Should you ever delay events in your cluster? Kind of interesting question. As engineers we are used to think that performance matters and delaying things goes directly against performance, right? Well, not always - there are quite a few cases in distributed environment when delaying things actually helps performance. For example, the most usual case is when you have a continuous stream of asynchronous computations on the grid. Since sending a computation is much faster than processing it, you can essentially overload grid and some sort of back pressure mechanism will be needed (usually you would just limit amount of active computations your grid can handle concurrently). However, in this blog I want to focus on delaying data operations rather than computations.
If you have heard about partitioned caching, then you perhaps know that whenever a new node joins the grid or an existing node leaves the grid, cluster repartitioning happens. This basically means that, in case of new node, it has to take responsibility for some of the data cached on other nodes, and in case of node leaving the grid, other nodes have to take responsibility for the data cached on that node. Essentially this results in data movement between data grid nodes. Picture below illustrates how keys get partitioned among caching data nodes (share-nothing-architecture):
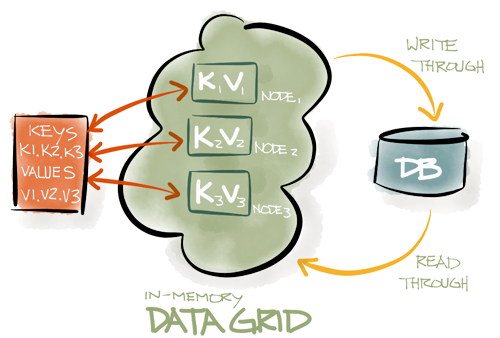
Now imagine that you need to bring multiple nodes up concurrently. The 1st node that comes up will take responsibility for some portion of the data cached on other nodes and will start loading that portion of the data from other nodes. When a 2nd node comes up, it will also take responsibility for some portion of the data, including some data from the 1st node that was just started, and now portion of the data that was moved to 1st node will have to be moved to the 2nd node. Ouch - wouldn't it be more efficient to wait till 2nd node comes up to start data preloading? The same happens when nodes 3, 4, etc... come up. So the most efficient way to do preloading of keys and to avoid extra network traffic causes by moving data between newly started nodes is to delay preloading until the last node starts.
At GridGain, we introduced this Delayed Preloading feature in our latest 4.2 release and now user is in full control of when data preloading happens - either right away upon node start, after a certain delay, or manually from our Visor Devops Console (note the Preload button on the right hand side):

As you see it does help to delay certain events in distributed systems to achieve better performance.
If you have heard about partitioned caching, then you perhaps know that whenever a new node joins the grid or an existing node leaves the grid, cluster repartitioning happens. This basically means that, in case of new node, it has to take responsibility for some of the data cached on other nodes, and in case of node leaving the grid, other nodes have to take responsibility for the data cached on that node. Essentially this results in data movement between data grid nodes. Picture below illustrates how keys get partitioned among caching data nodes (share-nothing-architecture):
Now imagine that you need to bring multiple nodes up concurrently. The 1st node that comes up will take responsibility for some portion of the data cached on other nodes and will start loading that portion of the data from other nodes. When a 2nd node comes up, it will also take responsibility for some portion of the data, including some data from the 1st node that was just started, and now portion of the data that was moved to 1st node will have to be moved to the 2nd node. Ouch - wouldn't it be more efficient to wait till 2nd node comes up to start data preloading? The same happens when nodes 3, 4, etc... come up. So the most efficient way to do preloading of keys and to avoid extra network traffic causes by moving data between newly started nodes is to delay preloading until the last node starts.
At GridGain, we introduced this Delayed Preloading feature in our latest 4.2 release and now user is in full control of when data preloading happens - either right away upon node start, after a certain delay, or manually from our Visor Devops Console (note the Preload button on the right hand side):

As you see it does help to delay certain events in distributed systems to achieve better performance.




View comments